Toy Example - Deep prior#
import tensorflow_probability as tfp
import tensorflow as tf
import numpy as np
import elicit as el
from bayesflow.inference_networks import InvertibleNetwork
tfd = tfp.distributions
---------------------------------------------------------------------------
ModuleNotFoundError Traceback (most recent call last)
Cell In[1], line 1
----> 1 import tensorflow_probability as tfp
2 import tensorflow as tf
3 import numpy as np
ModuleNotFoundError: No module named 'tensorflow_probability'
The Model#
Generative model#
Implementation#
Generative model#
class ToyModel:
def __call__(self, prior_samples, design_matrix):
# linear predictor
epred=tf.matmul(prior_samples[:, :, :-1], design_matrix,
transpose_b=True)
# data-generating model
likelihood = tfd.Normal(
loc=epred, scale=tf.expand_dims(prior_samples[:, :, -1], -1)
)
# prior predictive distribution
ypred = likelihood.sample()
# selected observations
y_x0, y_x1, y_x2, y_x3, y_x4 = (ypred[:,:,i] for i in range(5))
# R2
var_ypred = tf.math.reduce_variance(ypred, -1)
var_epred = tf.math.reduce_variance(epred, -1)
r2 = tf.math.divide(var_ypred, tf.add(var_ypred, var_epred))
return dict(
y_x0=y_x0, y_x1=y_x1, y_x2=y_x2, y_x3=y_x3, y_x4=y_x4,
r2=r2
)
Define design matrix#
# create a predictor ranging from 1 to 200
# standardize predictor
# select the 5th, 25th, 50th, 75th, and 95th quantile of the std. predictor for querying the expert
def x_design(n, quantiles):
x = tf.cast(np.arange(n), tf.float32)
x_std = (x-tf.reduce_mean(x))/tf.math.reduce_std(x)
x_sel = tfp.stats.percentile(x_std, quantiles)
return tf.stack([tf.ones(x_sel.shape), x_sel], -1)
x_design(n=200, quantiles=[5,25,50,75,95])
<tf.Tensor: shape=(5, 2), dtype=float32, numpy=
array([[ 1. , -1.5502049 ],
[ 1. , -0.85737586],
[ 1. , 0.00866036],
[ 1. , 0.85737586],
[ 1. , 1.5502049 ]], dtype=float32)>
Model input for elicit method#
# specify the model
model=el.model(
obj=ToyModel,
design_matrix=x_design(n=200, quantiles=[5,25,50,75,95])
)
Model parameters#
intercept parameter \(\beta_0\)
slope parameter \(\beta_1\)
error term \(\sigma\)
To be learned hyperparameters \(\lambda\): reflecting the weights of the deep neural networks within the normalizing flow architecture.
Parameter input for elicit method#
parameters=[
el.parameter(name="beta0"),
el.parameter(name="beta1"),
el.parameter(name="sigma", lower=0.)
]
Target quantities and elicitation techniques#
Target quantities
query expert regarding prior predictions \(y \mid X_{i}\) with \(i\) being the 5th, 25th, 50th, 75th, and 95th quantile of the predictor.
\(R^2 = \frac{\text{Var}(\mu)}{\text{Var}(y)}\) (we use \(\log R^2\) for numerical stability)
correlation between model parameters
Elicitation technique
query each prior prediction using quantile-based elicitation using \(Q_p(y \mid X)\) for \(p=5, 25, 50, 75, 95\)
query \(R^2\) using quantile-based elicitation using \(Q_p(y \mid X)\) for \(p=5, 25, 50, 75, 95\)
regarding the correlation structure, we assume independence between the model parameters (thus, \(\boldsymbol{\rho}_\boldsymbol{\theta}=\mathbf{0}\))
Importance of elicited statistics in loss
all elicited statistics should have equal importance (weight=1.0)
for computing the discrepancy between expert-elicited statistics and model simulations with use the Maximum Mean Discrepancy with Energy kernel
Targets input for elicit method#
targets=[
el.target(
name=f"y_x{i}",
query=el.queries.quantiles((.05, .25, .50, .75, .95)),
loss=el.losses.MMD2(kernel="energy"),
weight=1.0
) for i in range(5)
]+[
el.target(
name="r2",
query=el.queries.quantiles((.05, .25, .50, .75, .95)),
loss=el.losses.MMD2(kernel="energy"),
weight=1.0
),
el.target(
name="correlation",
query=el.queries.correlation(),
loss=el.losses.L2,
weight=0.1
)
]
Expert elicitation#
instead of querying a “real” expert, we define a ground truth (i.e., oracle) and simulate the oracle-elicited statistics
Expert input for elicit method (here: oracle)#
# specify ground truth
ground_truth = {
"beta0": tfd.Normal(loc=5, scale=1),
"beta1": tfd.Normal(loc=2, scale=2),
"sigma": tfd.HalfNormal(scale=5.0),
}
# define oracle
expert=el.expert.simulator(
ground_truth = ground_truth,
num_samples = 10_000
)
Normalizing Flow#
ToDo
network=el.networks.NF(
inference_network=InvertibleNetwork,
network_specs=dict(
num_params=3,
num_coupling_layers=3,
coupling_design="affine",
coupling_settings={
"dropout": False,
"dense_args": {
"units": 128,
"activation": "relu",
"kernel_regularizer": None,
},
"num_dense": 2,
},
permutation="fixed"
),
base_distribution=el.networks.base_normal
)
Training: Learn prior distributions based on expert data#
All inputs for elicit method
eliobj = el.Elicit(
model=model,
parameters=parameters,
targets=targets,
expert=expert,
optimizer=el.optimizer(
optimizer=tf.keras.optimizers.Adam,
learning_rate=0.001,
clipnorm=1.0
),
trainer=el.trainer(
method="deep_prior",
seed=4,
epochs=500
),
network=network
)
Run multiple chains
# run method
eliobj.fit(parallel=el.utils.parallel(chains=4))
---------------------------------------------------------------------------
_RemoteTraceback Traceback (most recent call last)
_RemoteTraceback:
"""
Traceback (most recent call last):
File "C:\Users\bockting\.conda\envs\prior_elicitation\Lib\site-packages\joblib\externals\loky\process_executor.py", line 426, in _process_worker
call_item = call_queue.get(block=True, timeout=timeout)
^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\bockting\.conda\envs\prior_elicitation\Lib\multiprocessing\queues.py", line 122, in get
return _ForkingPickler.loads(res)
^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\bockting\Documents\GitHub\prior_elicitation\elicit\__init__.py", line 6, in <module>
from . import initialization # noqa
^^^^^^^^^^^^^^^^^^^^^^^^^^^^
File "C:\Users\bockting\Documents\GitHub\prior_elicitation\elicit\initialization.py", line 5, in <module>
import tensorflow as tf
ModuleNotFoundError: No module named 'tensorflow'
"""
The above exception was the direct cause of the following exception:
BrokenProcessPool Traceback (most recent call last)
Cell In[31], line 2
1 # run method
----> 2 eliobj.fit(parallel=el.utils.parallel(chains=4))
File ~\Documents\GitHub\prior_elicitation\elicit\elicit.py:1179, in Elicit.fit(self, overwrite, save_history, save_results, parallel)
1176 seeds = parallel["seeds"]
1178 # run training simultaneously for multiple seeds
-> 1179 (*res,) = joblib.Parallel(
1180 n_jobs=parallel["cores"])(
1181 joblib.delayed(self.workflow)(seed) for seed in seeds)
1183 for i, seed in enumerate(seeds):
1184 self.results.append(res[i][0])
File ~\.conda\envs\prior_elicitation\Lib\site-packages\joblib\parallel.py:2007, in Parallel.__call__(self, iterable)
2001 # The first item from the output is blank, but it makes the interpreter
2002 # progress until it enters the Try/Except block of the generator and
2003 # reaches the first `yield` statement. This starts the asynchronous
2004 # dispatch of the tasks to the workers.
2005 next(output)
-> 2007 return output if self.return_generator else list(output)
File ~\.conda\envs\prior_elicitation\Lib\site-packages\joblib\parallel.py:1650, in Parallel._get_outputs(self, iterator, pre_dispatch)
1647 yield
1649 with self._backend.retrieval_context():
-> 1650 yield from self._retrieve()
1652 except GeneratorExit:
1653 # The generator has been garbage collected before being fully
1654 # consumed. This aborts the remaining tasks if possible and warn
1655 # the user if necessary.
1656 self._exception = True
File ~\.conda\envs\prior_elicitation\Lib\site-packages\joblib\parallel.py:1754, in Parallel._retrieve(self)
1747 while self._wait_retrieval():
1748
1749 # If the callback thread of a worker has signaled that its task
1750 # triggered an exception, or if the retrieval loop has raised an
1751 # exception (e.g. `GeneratorExit`), exit the loop and surface the
1752 # worker traceback.
1753 if self._aborting:
-> 1754 self._raise_error_fast()
1755 break
1757 # If the next job is not ready for retrieval yet, we just wait for
1758 # async callbacks to progress.
File ~\.conda\envs\prior_elicitation\Lib\site-packages\joblib\parallel.py:1789, in Parallel._raise_error_fast(self)
1785 # If this error job exists, immediately raise the error by
1786 # calling get_result. This job might not exists if abort has been
1787 # called directly or if the generator is gc'ed.
1788 if error_job is not None:
-> 1789 error_job.get_result(self.timeout)
File ~\.conda\envs\prior_elicitation\Lib\site-packages\joblib\parallel.py:745, in BatchCompletionCallBack.get_result(self, timeout)
739 backend = self.parallel._backend
741 if backend.supports_retrieve_callback:
742 # We assume that the result has already been retrieved by the
743 # callback thread, and is stored internally. It's just waiting to
744 # be returned.
--> 745 return self._return_or_raise()
747 # For other backends, the main thread needs to run the retrieval step.
748 try:
File ~\.conda\envs\prior_elicitation\Lib\site-packages\joblib\parallel.py:763, in BatchCompletionCallBack._return_or_raise(self)
761 try:
762 if self.status == TASK_ERROR:
--> 763 raise self._result
764 return self._result
765 finally:
BrokenProcessPool: A task has failed to un-serialize. Please ensure that the arguments of the function are all picklable.
Results#
Convergence#
el.plots.loss(eliobj, figsize=(7,3))
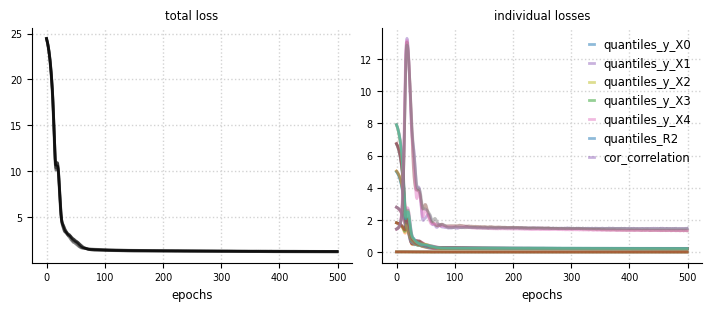
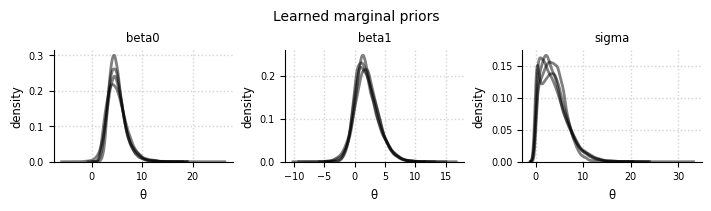
el.plots.marginals(eliobj, cols=3, figsize=(6,4))
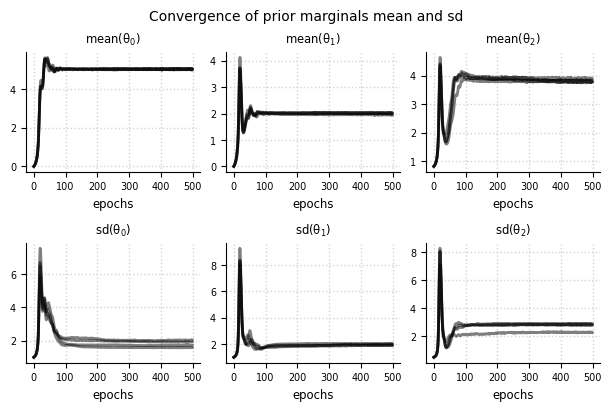
Expert expectations#
el.plots.elicits(eliobj, cols=4,figsize=(7,4))
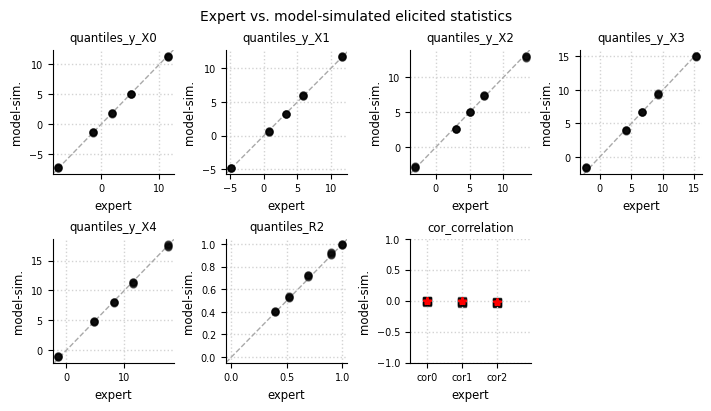
Learned joint prior#
el.plots.prior_joint(eliobj, idx=2)
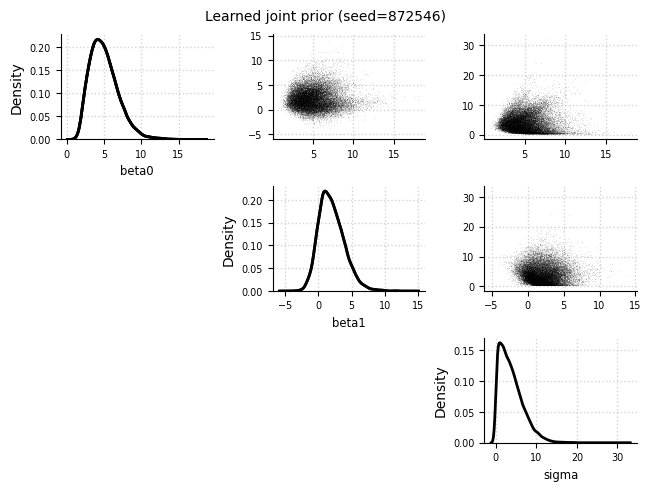
el.plots.prior_marginals(eliobj, figsize=(7,2))
INFO: Reset cols=3 (number of elicited statistics)
el.plots.prior_averaging(eliobj, figsize=(7,4))
INFO: Reset cols=3 (number of elicited statistics)
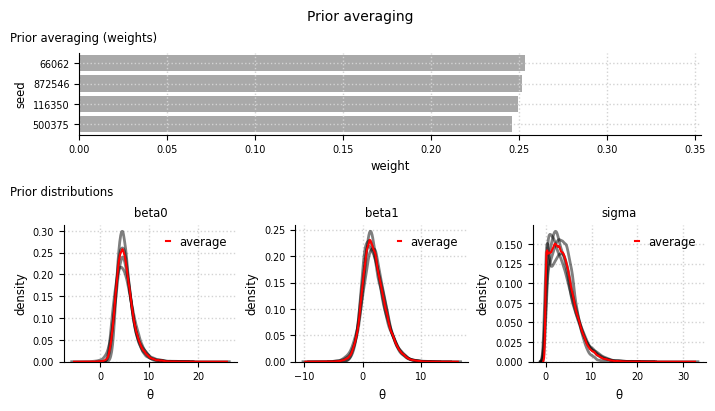
Add-on: Model averaging#
ToDo